Data Science

Tech Trends
Kicking It Up a Notch: Exploring Data Analytics in Soccer
The Major League Soccer (MLS) season's kickoff coincides with the rising tide of data analytics in soccer. Let's dive into the fascinating use cases and trends that reveal how data is informing decision-making in the world of soccer.


Alumni Stories
Troy Hendrickson: From Sales to Stats Auditor for the NBA
"I surprised myself with how much I enjoyed the learning process, Flatiron's values aligned perfectly with mine."

Artificial Intelligence
Hyperbolic Tangent Activation Function for Neural Networks
Activation functions play an important role in neural networks and deep learning algorithms. A common activation function is the hyperbolic tangent function, which is like the trigonometric tangent function, but defined using a hyperbola rather than a circle.

Alumni Stories
Jasmine Huang: Business to Data Science
“I love my job as an Actuarial Data Analyst, it’s exactly what I dreamed of.”

Alumni Stories
Milena Afeworki: Civil Engineering to Data Science
“Expect a learning curve where immediate progress might not be apparent. But keep persisting, and once those skills take root, you’ll be amazed by how far you’ve come.”
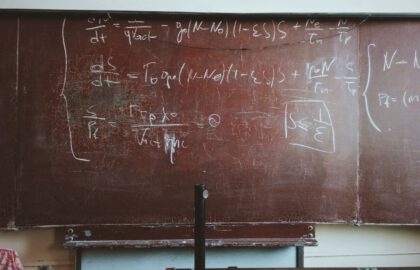
Data Science
How Much Math Do You Need to Become a Data Scientist?
While data science is built on top of a lot of math, the amount of math required to become a practicing data scientist may be less than you think.

Alumni Stories
Neda Jabbari, Ph.D.: Academic To Data Scientist
“Interacting with other students in my cohort and instructors with different backgrounds was my favorite part of the bootcamp.”