
The following is a guest post by John Richardson and originally appeared on his blog. John is currently in the Ruby-003 class at The Flatiron School. You can follow him on Twitter here.

Background: ADK 46-R
The ADK 46ers are a set of 46 mountains in upstate NY higher than 4000 feet. If you climb all of these mountains, keep records of your climbs, and then submit those records here, you can become a member of the 46-R club
ADK 46-R CLI
This project started as a Command Line Interface (CLI) that scrapped the following two sites for data on the mountains in the 46-R group and the associated hikes.
http://www.adk46er.org/peaks/index.html
http://www.everytrail.com/guide/adirondack-46er-list
The scrape loaded all the necessary data into a database and the CLI calls from that database when responding to user commands. The CLIT outputs the data in the following format:
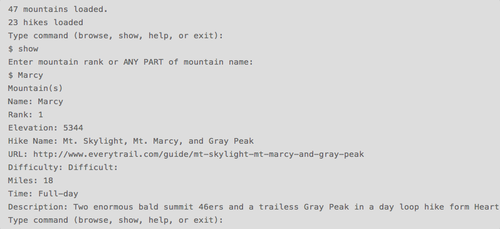
forty-sixer-on-rails
The next iteration of this project was using this data as the basis for a rails application that would allow users to view the mountains in the group, view the hikes in which those mountains could be hiked, and then keep track of their progress towards the goal of becoming an ADK 46-R. Before setting up the routes, controllers, views or any of that other good rails stuff, I needed to figure out how to get this data from my CLI applicaiton into my new rails application.
I didn’t want to just add the table to the rails database because I wanted the database to be integrated into ActiveRecord and the models I had designed for the application. I also didn’t want to hand write a massive seed file to get all this data into the database in my rails application.
Export to CSV
What I ended up doing was exporting the table from database that contained the scrapped data as a csv file and importating that csv file into the mountains and hikes tables in the rails database using the following commands:

I did this step for both the moutains and hikes tables which resulted in following two files: moutnains.csv and hikes.csv. I then went to the database in the forty-sixer rails project and did the following to import these two tables:

The .seperator command was an important step in getting the sqlite3 to undestanding the format of the data I was importing. Another important step was not using MS Excel to open and manipulate the csv file before I tried importating the csv file into the database. Initially I had opened the csv file in Excel and added to columns for created_at and updated_at in order for the columns in the csv file to line up with the columns in the rails database. Long story short, this did not work. What I ended up doing was removing the timestamps from the rails database and remigrating before I imported the csv file so that the columns in the rails databse and the CLI database were identical.
seed_dump
The rails application database constantly gets changed during development often getting dropped or reset. I wanted a way to make a seed file out of the data I had just worked so hard to get into my database. Here is where the ruby gem seed_dump saved the day.
Once installed in your gemfile, the following command:

will make seed files out of all the tables in your rails database. In other words, it took 47 rows (MacNaughton mountain is not on the official list, but its over 4000 ft) of this from the table
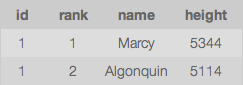
and turned it into 47 lines of ruby code in my seed file that looked like this

There are more elegent solution to this problem. For example, I could have added the scrape logic from the CLI application into the rails application and done the scrape directly from the rails applciation. On second thought, that would have been a lot easier. That’s what I get for working on this on the LIRR with no interent connection. At least now I have a backup plan next time I lose access to the internet or the data I need is only available through an existing database.



