
Deep learning has become an ever-growing part of the machine learning family. Part of its growth can be accredited to its compatibility with Python, a high-level programming language that’s also been rising in popularity since its creation in 1991.
While you can pick from a variety of languages to use with deep learning — such as C++, Java, and LISP — Python remains the first choice for millions of developers worldwide. The powerful open-source TensorFlow and PyTorch libraries (developed by Google and Facebook, respectively) provide a straightforward interface for Python developers to build neural networks.
What is the difference between deep learning and machine learning?
In order to understand both the differences between deep learning and machine learning, you first need to dip your toes into the concept of Artificial Intelligence (AI).
AI is the science of simulating human intelligence in machines, allowing them to recognize patterns, analyze situations, and come up with suitable reactions. However, AI is a broad concept. If a machine can ‘think’, then it’s an AI. How you achieve the desired level of intelligence is where the various subsets of AI come into play.
Machine learning

Machine learning, a subset of AI, is a learning process in which structured data is fed to a machine. Without machine learning, the developer would have to manually program and implement all the needed algorithms and rules the AI system would need to function.
The success of a machine learning operation relies primarily on two factors: quality and quantity of the data. The structured data needs to be accurate and to prioritize one characteristic that you want the machine to learn to recognize. As for quantity, the more variants of the same type of data the machine received, the better its understanding of the subject matter.
How the machine learns is divided into multiple categories depending on how the data is presented and whether the machine received direct or excessive assistance from humans.
Supervised learning consists of feeding computers training data along with human participation to help train it on how to respond to said data. Semi-supervised learning gives the machines a level of independence by supplying them with a mixture of labeled data points along with unlabeled, but related, data. The computer is then required to identify the unlabeled objects according to what it ‘thinks’ is correct.
However, those two methods are limiting. They require massive volumes of data, labeled and unlabeled, as well as consistent and reliable human participation, which makes working on bigger projects a challenge. Other subsets of machine learning are different. They convert the majority of the work towards the machine, only involving humans in the early stages of the build.
Unsupervised learning — and its subset, self-supervised learning — as the name suggests, feeds computers unlabeled data. This practice gives the machines complete freedom to find patterns and categorize objects and data points accordingly.
While machine learning is the practice of teaching computers to think like people, deep learning is one of the methodologies. It cannot be separated from machine learning as a whole. By applying any of the previously mentioned machine learning approaches, the machine still thinks like a computer running a step-by-step program, albeit a complex one.
Some examples of machine learning algorithms that would not be considered deep learning are linear regression, random forests, and k-nearest neighbors. Of these, k-nearest neighbors is probably the most intuitive; essentially it is following the real estate practice of finding “comps” (other data points that are similar) and giving an answer based on averaging those values. You can see how this is teaching a computer to “think”, but only in a narrow, limited way.
Deep learning
Deep learning, on the other hand, is a subset of machine learning that applies neural networks rather than simple algorithms. While it still relies on teaching machines human-like thinking skills, it takes a different, more sophisticated approach. Instead of relying on simple machines to make sense of your data, it changes how a machine’s ‘brain’ receives and processes training data.
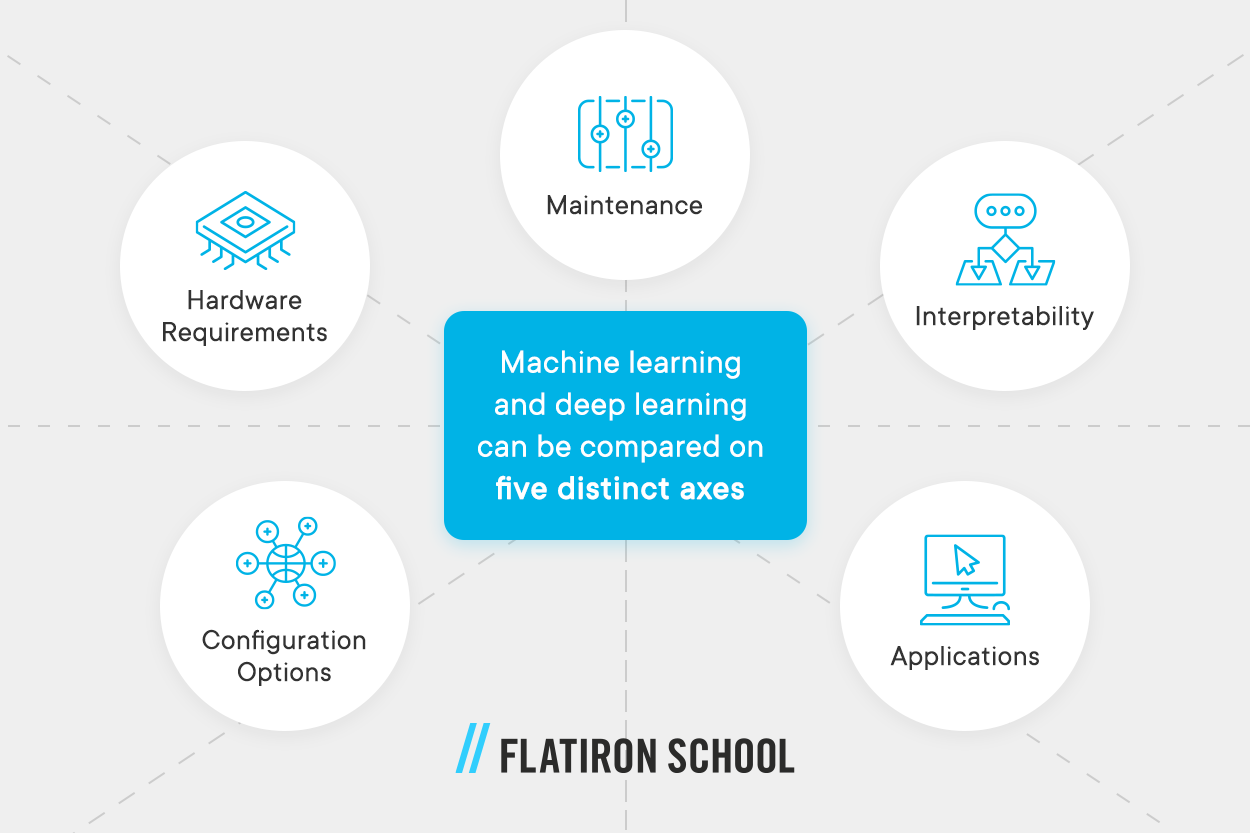
Based on this explanation, machine learning and deep learning can be compared on five distinct axes:
- Maintenance: While both deep learning and machine learning require human intervention — including self-supervised and unsupervised learning — they vary in the specific details. Traditional machine learning requires ongoing human intervention, while deep learning only needs human assistance early on.
- Hardware Requirements: Traditional machine learning is simpler and doesn’t require powerful hardware. You can run a machine learning app on an average laptop. Most deep learning, on the other hand, requires a powerful hardware infrastructure to support its complex neural network.
- Configuration Options: Traditional machine learning algorithms tend to have relatively few configuration options (also known as hyperparameters), so the developer only has a few decisions to make, mostly around selecting the appropriate balance between underfitting and overfitting. Deep learning requires more developer skill because there are many different kinds of layers, architectures, and optimization functions to choose from, each of which will have minute but important impacts on the results.
- Interpretability: For some traditional machine learning models, it is straightforward to explain how the model made its predictions using the given inputs. With deep learning, the model is more of a “black box” because the decision-making process is so much more complex.
- Applications: Traditional machine learning works well in relatively simple situations such as revenue forecasting, where all of the input variables are numbers. Thanks to the complex nature of deep learning, it can be used in scenarios with more advanced input data types such as self-driving cars and facial recognition.
What is deep learning?
To bypass the rigid nature of computers, complex and multi-layered deep neural networks are built and used as a base for learning. Instead of operating like a serial program, deep learning models work using networks joined by nodes — similar to how the human brain uses millions of connected neurons to function. It’s the combination of engineering advances, best practices, and theory that enables a wealth of previously impossible smart applications.
Despite still being a programmable machine, deep learning systems don’t process data like your average computer. A single deep neural network consists of multiple layers — the more layers there are, the more accurate the results. But instead of working separately or taking turns, they build upon each other’s work. While neural networks vary in how they work, and not all of them process data in a linear fashion, they all have a similar foundation.
Instead of working with the raw data of the input all over again, each layer works with a slightly more refined and optimized version based on the previous layer’s prediction and categorization. The work the machine does within the layers remains mostly hidden, with the exception of input and output layers, also known as the ‘visible layers’.
How the nodes are arranged and communicate with each other is dictated by the deep learning algorithm used. Usually, engineers would use different algorithms depending on available resources and goals.
Convolutional neural networks
Convolutional neural networks (CNNs) are designed with images as the input in mind. This type of network breaks the input image into pixels, handing each pixel to a single node in the second layer. Each node analyzes the pixel for its content. After multiple layers of analysis, the nodes then combine their findings to identify the relevant features of the image and attempt to guess what the image represents. This approach allows the model to detect features like edges and curves without explicitly being trained to do so.
CNNs, in particular, benefit from a high number of layers. The deeper the pixel information travels into the neural network, the more features they begin to identify. With enough layers, CNNs can differentiate between objects and people.
Recurrent neural networks
Recurrent neural networks (RNNs) are sometimes called hidden layers networks because of how information travels between the nodes. Instead of moving on to the nodes in the next layers, information in RNNs will loop and go back into the same node for further analysis.
This looping makes RNNs perfect for sequential or time-tagged data that needs to be in a certain order to be perceived accurately. One example is language translation. Not only does the algorithm have to find the right words in the target language by ‘understanding’ the context and fetching a synonym, but it also needs to produce the output in the right order. Otherwise, the program has failed.
Long short-term memory networks
As the name suggests, long short-term memory networks (LSTMs) are a type of RNN. In addition to the multiple layers that they have, LSTMs are capable of storing and recalling information from past processing sessions. That allows them to excel at time-series predictions by building upon previous data instead of starting from scratch.
Instead of the input information going one way from the input layer to the output, it can go back and forth between the inner layers as they communicate semi-freely with each other. This chain-like structure allows LSTMs to be used in speech recognition, in music composition, and even in developing pharmaceuticals.
What is deep learning using Python?
While machine learning only requires a well-built database of training objects, deep learning demands a complex infrastructure of neural networks consisting of countless nodes all interacting together in various directions. Each node and its connections aren’t complex on their own. In fact, because a single node does so little work compared to the entirety of the neural network, it’s considered a relatively simple structure.
However, creating thousands of nodes easily rounds up to a lot of time and effort. The more complex the programming language you’re using, the harder it would be to construct a working network.
Python, compared to other data-focused programming languages, is extremely easy to use and learn. After all, it’s a high-level programming language, meaning it’s closer to spoken human languages — English, in particular — than the available alternatives. Not to mention, Python’s community of passionate users and learners all contribute to evolving the language by publishing in-depth tutorials and guidebooks online, as well as adding items to ready-use code libraries.
Additionally, the primary ingredient in all deep learning algorithms and applications is data, both as input and as training material. Python is mainly used for data managing manipulation and forecasting, making it an excellent tool to use for managing massive volumes of data for training your deep learning system, inserting input, or even making sense out of its output.
How to study deep learning with Python
Exploring the world of deep learning using Python is a never-ending journey. There would always be a new technique to learn, a new algorithm to improve on, and another expert to take advice from. One of the best ways you can take your deep learning with Python skill to the next level is by studying the projects and books of experts in the field.
For starters, the book “Deep Learning with Python” is an excellent way to dip your toes into deep learning. It’s written by the Keras Python library and the Google AI researcher Françios Chollet. But instead of being a technical jumble, “Deep Learning with Python” builds your understanding using intuitive explanations and practical examples.
Alternatively, if you have your mind set on one of the most needed and futuristic machine learning and deep learning applications, you can always pick up “Deep Learning for Computer Vision with Python“, written by the author and entrepreneur Adrian Rosebrock. Not only is this book beginner-friendly, but it’ll take you on a step-by-step journey into mastering machine learning and deep learning using convolutional neural networks.
The 8 best Python machine learning libraries

While ease of use, power, and simplistic layout all play a role in making Python the ideal coding language for machine learning in general and deep learning in particular, it’s actually Python’s libraries that win the race.
Python, compared to the countless other programming languages out there, has the biggest selection of open-source chunks of code that are available online for free in the forms of Python libraries. But unlike real-life libraries, each Python library carries code that works in a specific area only. For instance, the libraries you’d use to develop an app or website using Python often aren’t the same ones you’d need when working with databases — with some exceptions.
So as a beginner Python programmer with an interest in machine learning, which libraries should you expect to use regularly in your projects?
Luckily, you don’t have to worry about shortages of code, as there are 8 highly recommended Python libraries for deep learning programmers.
1. TensorFlow
TensorFlow is a math symbolic, mathematics library that utilizes dataflow and differentiable programming in its code. It’s a free and open-source library made specifically for machine learning. But while you can use it whichever way you deem fit, TensorFlow can be of great help when it comes to developing deep neural networks.
2. PyTorch
PyTorch is an open-source, machine learning Python library that’s based on the popular Torch library. It was first developed by Facebook’s AI research lab and mainly used for computer vision and natural language processing applications. While the code in the library is completely free to use, it’s under the modified BSD license, requiring a level of citation.
3. Keras
Keras is an open-source, Python deep learning application programming interface (API). So, instead of providing you with the code for the inner workings of your AI software, Keras mainly provides a simple and palatable interface — often used with the TensorFlow library.
4. NumPy
As the name suggests, NumPy’s collection of code is mainly used in high-level mathematical functions and data processing. You can use it to expand your networks by allowing support of large, multi-dimensional arrays and matrices all in one go.
5. Scikit-Learn
SciKit-learn, also known as sklearn, is a free machine learning library that allows you to process the more technical — or scientific — parts of your AI system. Its countless features include clustering, classification, and regressions algorithms, along with support for vector machines, random forests, and gradient boosting. Scikit-learn doesn’t work solo. It’s designed to be integrated and used alongside Python’s other technical libraries like NumPy and SciPy.
6. Pandas
Pandas is probably one of the most well-known code libraries ever written for Python. It’s a database of code designed specifically to manipulate and analyze massive volumes of data using Python. You can use it for setting up data structures and performing complex operations on numerical tables and time-series datasets. While it’s free to use, it falls under the three-clause BSD license.
7. Matplotlib
Matplotlib is a plotting library designed to work alongside Python’s NumPy. But instead of a user interface, Matplotlib provides code for object-oriented API allowing you to embed plots into your apps using only general graphical user interface (GUI) toolkits.
8. Theano
While Theano can be considered yet another mathematical Python library, it stands out thanks to its ability to manipulate and evaluate mathematical expressions, matrix-valued, in particular. You don’t need special hardware as Theano can run on either CPU or GPU architecture and can be used alongside other numeric and technical Python libraries.
Where can I start learning Python for Free?
Thanks to the countless online resources available to learn Python for free, you can start your journey towards becoming a Python machine learning programmer. To test the waters, sign up for Flatiron School’s free Python lesson to get started with the basics.
Alternatively, if this article made sense to you and you’re looking to dive into a career based on learning Python for deep learning, you can book a free 10-minute chat with admissions to get you on the right path.



