Over 80% of the TV shows and movies we watch on Netflix are being discovered through its internal recommendation system.
Yish Lim, data science instructor at Flatiron School, breaks down the algorithm, data science, and machine learning behind how Netflix curates these recommendations, and how you can write your very own algorithms.
“The Science Behind Netflix Recommendations” was a popular online event hosted by Flatiron School. Join us for a future event to learn how data science contributes to the world.
Here's the video if you want to watch the full recording at once. Otherwise, we break it down in the article below.
Key Takeaways:
-
A recommendation engine is a type of data tool that uses machine learning and algorithms to learn about a user's preferences and make recommendations based on those preferences.
-
There are three main types of recommendation engines — non-personalized, content-based, and collaborative filtering.
-
Yish’s research shows that Netflix uses a hybrid model of content-based and collaborative filtering.
Event Overview:
-
Intro to recommendation engines
-
-
Non-personalized recommendation engines
-
Content-based recommendation engines
-
Collaborative filtering recommendation engines
-
-
How Netflix makes recommendations
-
Coding examples to build recommendation engines
-
Questions from the live event
Note: We are not affiliated with Netflix and their algorithms are not publicly available. This is an educated guess based on research.
Part 1: An Introduction to Recommendation Engines
Let’s start with why we need recommendations and some examples.
Of course, Netflix is a recommendation engine, but Spotify is a pretty great one as well.
A less popular example of recommendation engines are ads. Of course they’re annoying, but those targeted ads that you see on Facebook and Instagram are also recommendation engines built on the same kinds of algorithms.
There are three main types of recommendation engines — non-personalized, content-based, and collaborative filtering.
1. Non-personalized recommendation engines
If you go onto YouTube as a completely brand-new user, you still get a bunch of things recommended to you. Even in incognito mode, where the site doesn’t know who you are, you will get recommendations based on things that are trending.
The idea of non-personalized recommendation engines is that anyone who’s a brand-new YouTube user will get non-personalized recommendations filtered by location, trending, or even based on data from Google such as age and location. But for the most part there isn’t too much personalization going on here.
What’s a practical way to use non-personalized recommendations? If you're a brand-new company or store and you want to push products to customers, maybe instead of trying to figure out what each individual person would like, you push your most popular product. Or maybe you push the product that you think will get the highest ROI.
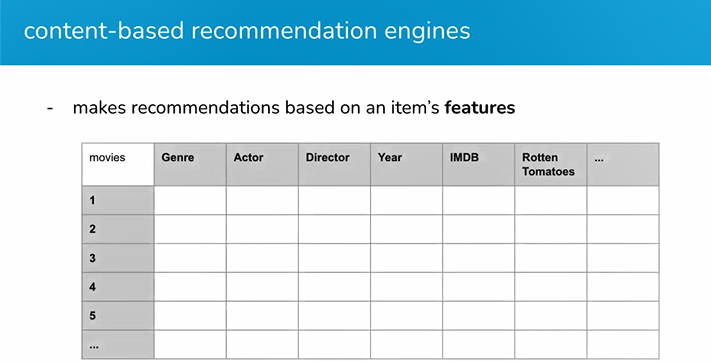
2. Content-based recommendation engines
With content-based recommendation engines, you start to get a little bit more personalization. Content-based recommendations are recommendations based on previous watched or viewed items.
For example, if you spend a weekend watching TikTok videos about cooking, you will soon realize that all of your future TikTok recommendations are going to be cooking videos.
A content-based recommendation engine makes recommendations based on an item’s features, like in this grid:
Pros and cons of content-based recommendations
Content-based recommendations can be quite limiting. If you only have limited information about an individual, you are likely to pigeonhole them rather than recommending more variety.
For example, let’s say you like Nickelback even though many people think their music is “awful.” If someone were to make content-based recommendations, you would get recommendations for ‘music that sounds like Nickelback’ rather than expanding your horizon to ‘other music that people think is awful.’
3. Collaborative filtering
Collaborative filtering is an umbrella term for any sort of algorithm that makes recommendations for items based on the ratings of other users.
There are many different ways to do collaborative filtering, but the most popular one that was actually popularized by Netflix is called Singular Value Decomposition (SVD).
Singular Value Decomposition (SVD) does require some complicated math by combining calculus, linear algebra, and machine learning.
Watch as Yish explains this process:
Gradient Descent
So, to move on we actually have to talk a little bit about gradient descent which is basically what machine learning is built off of. So, machine learning I know it sounds pretty scary especially for those of you who haven’t experienced or learned about machine learning yet. Machine learning is something that we teach right about the halfway point of our course and is really, really interesting it is actually very, very elegant. The way a machine learns is let’s say I want to figure out, maybe I want to figure out okay this is not exactly how it works so let’s say I want to train a computer how to play chess.
Collaborative Pros and Cons
Pros: Ratings are heavily personalized
Con: It is a little bit computationally heavy and requires a lot of calculation
Popularity bias doesn’t could for an individual’s very unique preferences.
Part 2: How does Netflix make recommendations?
As you can imagine, collaborative filtering is a bit challenging on Netflix since its utility matrix is so massive. Yish has done the research and explains how Netflix uses a hybrid model of content based and collaborative filtering.
The Netflix Algorithm
Data Science Process
Next, Yish walks through the data science process, and how it is applied to a simple movie recommendation system.
Questions from this live event
Q: Can you bias your results by choosing a bad train test split schema?
A: Absolutely, yes that’s actually something we talk about pretty in depth when we get to machine learning in our course as well. So, if you happen to have a randomized train test split (that maybe all of your one rating just happened to be in your test set) it really does bias how the model trains.
A process that we use to mitigate that is called cross validation, and you can actually do multiple train test splits to see if there are big fluctuations in your modeling results. So, let’s say with one particular train test split, while your model only predicts like 0.1 stars off. That’s great, but on your test set or maybe on a different train test the same model does really poorly. So that is something that you can do to mitigate that problem and it’s known as overfitting.
Q: How long have you been studying machine learning and data analysis? Where do you recommend starting?
A: I started Flatiron School’s program at the end of 2018. Prior to that, I did have an Econ major, which was kind of quantitative, but I had zero coding experience when I joined the program. Upon doing the program, I fell in love with machine learning and have been continuously studying machine learning ever since.
Where do I recommend starting? If you're interested in implementing machine learning, as you saw with this code, I just had to figure out what to code. I actually didn’t have to figure out a lot of the math behind this model.
So, if you're more interested in implementing, start with Python to get used to coding, and get used to reading documentation and libraries. If you do that, you’ll be able to just look up, “Okay. Is there a library for this kind of machine learning?” And you’ll be able to just plug in your data and use it. If you're more interested in actual machine learning theory, it is important to get into math. If you want to create your own machine learning algorithm, definitely calculus is going to be important.
Q: Any tips for success in the bootcamp?
A: Bootcamp is very, very intense. I did a full time program in 15 weeks, and burnout can really happen. I think the main advice that I now give to students is to be okay with not understanding everything. We move at a pretty fast pace — the material that we cover encompasses three or four semesters of college work in a single semester’s amount of time.
We also have a flex program as an option if the 15 weeks feels a little bit too aggressive. Or maybe you just don’t have the capability, based on your schedule, to actually do a full-time program. You can do the flex option in 20, 40, or 60 weeks.
Know yourself before coming in because I think sometimes some students bite off more than they could chew in the program, and don't necessarily approach it strategically based on the workload.
Q: What courses do you teach and what would you recommend for a high school student who may not have been introduced to high levels of math yet?
A: I teach the data science program which includes Python and a little bit of statistics.
Experience with learning how to code will be able to bring you to all different directions. So, I do recommend maybe taking up Python. Do a little bit of research on what kind of coding you’d be interested in and then go from there.
Q: What is the difference between data science and software engineering?
A: To grossly generalize, data science is more about doing machine learning and predictive algorithms. But very little front end as we don’t code out websites and stuff like that. Software engineering does more like apps, websites, more like front facing stuff.
I would say think of a data scientist as someone that’s trying to solve a particular business problem or an organizational issue. They’re trying to figure out what the actual problem is, trying to help allocate resources, trying to help inform decisions based on data, whether it’s current or future decisions with predictive modeling.
With software engineering, more times than not you're building a product, you're actually developing a full fledged interactive product for public use.
Jelani: Do you have to learn a specific programming language or is it open to any?
Yish: Python and R are the most common programming languages for data science. Python is typically the first one taught because it is easy to implement.
Q: What is back testing?
A: Yish: Back testing is a different term for validating your model. So, if Netflix had implemented this model, but let’s say a bunch of people are complaining “Hey my recommendations that I’m getting they’re awful,” so there is a bit of back testing. Usually there is rolled out testing to assume they are missing some data and then test their model using that.